Quality Assurance for Machine-Learning Pipelines
This post covers some content from the “Infrastructure Quality” lectures of our Machine Learning in Production course. For other chapters see the table of content.
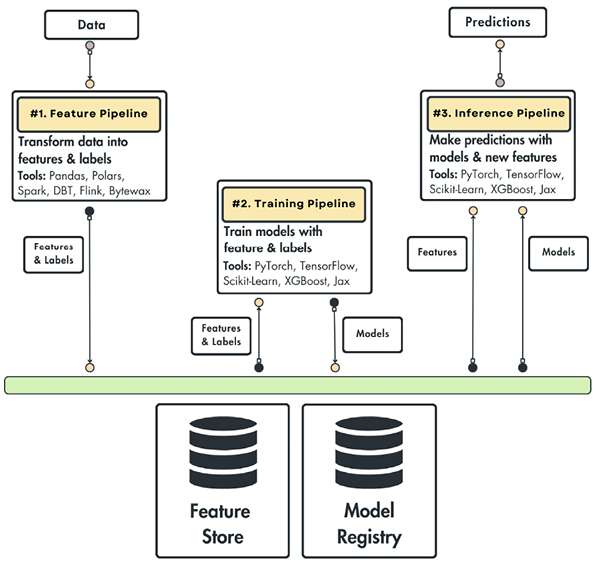
Machine-learning pipelines contain the code to train, evaluate, and deploy models that are then used within products. As with all code, the code in a pipeline can and should be tested. When problems occur, code in pipelines often fails silently, simply not doing the correct thing, but without crashing. If nobody notices silent failures, problems can go undetected for a long time. Problems in pipelines often result in models of lower quality. Quality assurance of pipeline code becomes particularly important when pipelines are executed regularly to update models with new data.
Since machine-learning pipelines are code, they can be assured like other code in a software system. While machine-learned models are difficult to test (as discussed in previous Model Quality chapters), pipeline code is not really different from traditional code: it transforms data, calls various libraries, and interacts with files, databases, or networks. This makes pipeline code much more amenable to the traditional software quality assurance approaches surveyed in chapter Quality Assurance Basics. In the following, we will discuss testing, code review, and static analysis for pipeline code.
Silent Mistakes in ML Pipelines
Most data scientists can share stories of mistakes in machine learning pipelines that remained undiscovered for a long time. In some cases, there were undiscovered problems from the beginning, and, in other cases, some external changes broke something but went unnoticed. Consider the example of a grocery delivery business with cargo bikes that, when faced with data drift, continues to collect data and regularly retrains a model to predict demand and optimal delivery routes every day.
- At some point, the dataset is so big that it no longer fits the virtual machine used for training. Training of new models fails, but the system continues to operate with an old model. The problem is only discovered weeks later when model performance in production has degraded to the point where customers start complaining about unreliable delivery schedules.
- The process that extracts additional training data from recent orders crashes after an update of the database connector library. Training data is hence no longer updated, but the pipeline continues to train a model every day based on exactly the same data. The problem is not observed by operators who see successful training executions and stable reports of the offline accuracy evaluation every day.
- An external commercial weather API provides part of the data used in training the model. When the weather API is unreachable the data is recorded with n/a values, which are later replaced with default values in a later data-cleaning step of the pipeline. When the credit card for payment expires, the weather API rejects requests, but this is not noticed for a long time because the pipeline still produces a model, albeit based on lower-quality data with default values instead of real weather data.
- During feature engineering, times of orders are encoded cyclically to better fit the properties of the machine-learning algorithm and to better handle predictions around midnight. Unfortunately, due to a coding bug, the learning algorithm receives the original untransformed data. It still learns a model, but a weaker one than had the data been transformed as intended.
- The system collects vast amounts of telemetry. As the system becomes popular, the telemetry server gets overloaded, dropping almost all telemetry submitted from mobile devices of delivery drivers. Nobody notices that the amount of collected telemetry does not continue to grow with the number of drivers and problems experienced by drivers users go undetected until users complain en masse in reviews on the app store.
A common theme here is that none of these problems manifest as a crash. We only observe these problems if we proactively monitor for the right issues in the right places. Silent failures are typically caused by a desire for robust executions and a lack of quality assurance of what is perceived as “just” infrastructure code: First, machine learning algorithms are intentionally robust to noisy data, so that they still train a model even when the data was not prepared, normalized, or updated as intended. Second, pipelines often interact with many other parts of the system, such as components collecting data, data storage components, components for data labeling, infrastructure executing training jobs, and components for deployment. Those interactions with other parts of the system are rarely well specified or tested. Third, pipelines often consist of scripts executing multiple different steps and it may appear to work even if individual steps fail when subsequent steps can work with incomplete results or intermediate results from previous runs. Error detection and error recovery code is often not a priority in data-science code, even when it is moved into production.
Code Review for ML Pipelines
All data science code can be reviewed just like any other code in the system. This can include incremental reviews of changes, but also deeper inspections of specific code fragments before deployment. As discussed in chapter Quality Assurance Basics, code reviews can provide many benefits at moderate costs, including discovering problems, sharing knowledge, and creating awareness in teams. For example, data scientists may discover problematic data transformations or learn tricks from other data scientists when reviewing their code or may provide suggestions for better modeling.
During early exploratory stages, it is usually not worth it to review all changes to data science code in a notebook, while code is constantly changed and replaced (see also chapter Data Science and Software Engineering Process Models). However, once the pipeline is prepared for production use, it may be a good idea to review the entire pipeline code, and from there review any further changes using traditional code review. When a lot of code is migrated into production, a separate more systematic inspection of the pipeline code (e.g., an entire notebook, not just a change) could be useful to identify problems or collect suggestions for improvement. For example, a reviewer might suggest normalizing a feature before training or notice that the line df["count"].astype(str).astype(int) does not actually change any data, because it does not perform operations in place.
Code review is particularly effective for data science issues that are difficult to find with testing, such as inefficient encoding of features, poor handling of data quality issues, or poor protection of private data. Beyond data-science-specific issues, code review can also surface many other more traditional problems, including style issues and poor documentation, library misuse, inefficient coding patterns, and traditional bugs. Checklists are effective to focus code review activities and guide reviewers in systematically looking for issues that may be otherwise hard to find.
Testing Pipeline Components
Testing deliberately executes code with selected inputs to observe whether the code behaves as expected. Code in machine-learning pipelines that transforms data or interacts with other components in the system can be tested just like any other code.
Testability and modularity (“from notebooks to pipelines”)
It is much easier to test small and well-defined units of code than big and complex programs. Hence, software engineers typically decompose complex programs into small units (e.g., modules, objects, functions) that can each be specified and tested independently. Every single if statement in a program can double the number of paths through the program that may need to be tested, increasing complexity exponentially with the number of decisions. When a piece of code has few internal decisions and limits interactions with other parts of the system, it is much easier to identify inputs that represent the various expected (and invalid) execution paths.
Much data-science code is initially written in notebooks and scripts, typically with minimal structure and abstractions, but with many global variables. Data science code is also typically self-contained in that it loads data from a specific source and simply prints results, often without any parameterization. All this makes data-science code in notebooks and scripts difficult to test, because (1) we cannot easily execute the code with different inputs, (2) we cannot easily isolate and separately test different parts of the notebook independently, and (3) we may have a hard time automatically checking outputs if they are only printed to the console.
In chapter Automating the ML Pipeline, we argued to migrate pipeline code out of notebooks into modularized implementations (e.g., individual function or component per transformation or pipeline stage). This modularization is also very beneficial to make the pipeline more testable. That is, the data transformation code in the middle of a notebook that modifies values in a specific data frame can be converted into a function that can work on different data frames and that returns the modified data frame or the result of the computation. This function can now intentionally be tested by providing different values for the data frame and observing whether the transformations were performed correctly, even for corner cases.
# typical data science code from a notebook
df = pd.read_csv('data.csv', parse_dates=True)
# data cleaning
# ...
# feature engineering
df['month'] = pd.to_datetime(df['datetime']).dt.month
df['dayofweek']= pd.to_datetime(df['datetime']).dt.dayofweek
df['delivery_count'] = boxcox(df['delivery_count'], 0.4)
df.drop(['datetime'], axis=1, inplace=True)
dummies = pd.get_dummies(df, columns = ['month', 'weather', 'dayofweek'])
dummies = dummies.drop(['month_1', 'hour_0', 'weather_1'], axis=1)
X = dummies.drop(['delivery_count'], axis=1)
y = pd.Series(df['delivery_count'])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# training and evaluation
lr = LinearRegression()
lr.fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))# after restructuring into separate function
def encode_day_of_week(df):
if 'datetime' not in df.columns: raise ValueError("Column datetime missing")
if df.datetime.dtype != 'object': raise ValueError("Invalid type for column datetime")
df['dayofweek']= pd.to_datetime(df['datetime']).dt.day_name()
df = pd.get_dummies(df, columns = ['dayofweek'])
return df
# ...
def prepare_data(df):
df = clean_data(df)
df = encode_day_of_week(df)
df = encode_month(df)
df = encode_weather(df)
df.drop(['datetime'], axis=1, inplace=True)
return (df.drop(['delivery_count'], axis=1),
encode_count(pd.Series(df['delivery_count'])))
def learn(X, y):
lr = LinearRegression()
lr.fit(X, y)
return lr
def pipeline():
train = pd.read_csv('train.csv', parse_dates=True)
test = pd.read_csv('test.csv', parse_dates=True)
X_train, y_train = prepare_data(train)
X_test, y_test = prepare_data(test)
model = learn(X_train, y_train)
accuracy = eval(model, X_test, y_test)
return model, accuracyExample of linear and abstraction-free data science code from a notebook and how it can be split into multiple separate functions.
All pipeline code — including data acquisition, data cleaning, feature extraction, model training, and model evaluation steps — should be written in a modular, reproducible, and testable implementations, typically as individual functions with clear inputs and outputs and clear dependencies to libraries and other components in the system (if needed).
Many infrastructure offerings for data-science pipelines now support writing pipeline steps as individual functions with the infrastructure then handling how to schedule executions and move data between functions. For example, data flow frameworks like Luigi, DVC, Airflow, d6tflow, and Ploomber can be used for this orchestration of modular units, especially if steps are long running and should be scheduled and distributed flexibly. Several cloud providers provide services to host and execute entire pipelines and experimentation infrastructure with their infrastructure, such as DataBricks and AWS SageMaker Pipelines.
Automating tests and continuous integration
To actually test code in pipelines, we can return to standard software testing tools. Typically tests are written in a testing framework so that all tests can be automatically executed with the testing framework’s test driver. For Python code, pyunit is a popular test driver that executes all test functions within a file and reports test results.
def test_day_of_week_encoding():
df = pd.DataFrame({'datetime': ['2020-01-01','2020-01-02','2020-01-08'], 'delivery_count': [1, 2, 3]})
encoded = encode_day_of_week(df)
assert "dayofweek_Wednesday" in encoded.columns
assert (encoded["dayofweek_Wednesday"] == [1, 0, 1]).all()
# more tests...Example of a test for the `encode_day_of_week` function, checking that the function correctly adds a column to the dataframe with expected encoded values for the day of the week.
Similarly, it is possible to write a test of the entire pipeline (essentially integration tests), executing the entire pipeline with deliberate input data and checking whether the model evaluation result meets the expectation.
def test_pipeline():
train = pd.read_csv('pipelinetest_training.csv', parse_dates=True)
test = pd.read_csv('pipelinetest_test.csv', parse_dates=True)
X_train, y_train = prepare_data(train)
X_test, y_test = prepare_data(test)
model = learn(X_train, y_train)
accuracy = eval(model, X_test, y_test)
assert accuracy > 0.9Example of an integration test that executes multiple pipeline steps together, but on fixed test data with given accuracy expectations.
All these tests can now also be executed as part of continuous integration whenever the pipeline code is modified (see chapter Quality Assurance Basics).
Minimizing and stubbing dependencies
Small modular units of code with few external dependencies are much easier to test than larger modules with complex dependencies. For example, data cleaning and feature encoding code is much easier to test if it receives the data to be processed as an argument to the cleaning function rather than retrieving such data from an external file. For example, we can intentionally feed different inputs to function encode_day_of_week in our example, which was not possible when the data source was hardcoded in the original non-modularized code.
Importantly, testing with external dependencies is usually not desirable if these dependencies may change between test executions or if they even depend on the live state of the production system. It is generally better to isolate the tests from such dependencies if they are not relevant to the test. For example, if the tested code sends a request to a web API to receive data, the output of the computation may change as the API returns different results, making it hard to write concrete assertions for the test. If a database is sometimes temporarily unavailable or slow, test results can appear flaky even though the pipeline code works as expected. While there is value in also testing the interaction of multiple components, it is preferable to test behavior as much in isolation as possible to reduce complexity and avoid noise from irrelevant interference.
Not all dependencies are easy to eliminate. If moving calls to external dependencies is not feasible or desired, it is possible to replace these dependencies with a stub (or mock or test double) during testing. A stub implements the same interface as the external dependency, but provides a simple fixed implementation for testing that always returns the same fixed results, without actually using the external dependency. More sophisticated mock object libraries, such as unittest.mock, can help write objects with specific responses to various calls. The tests can now be executed deterministically without any external calls.
# original implementation hardcodes external API
def clean_gender_original(df):
def clean(row):
if pd.isnull(row['gender']):
row['gender'] = gender_api_client.predict(row['firstname'],
row['lastname'], row['location'])
return row
return df.apply(clean, axis=1)
# decouple implementation from API
def clean_gender(df, model):
def clean(row):
if pd.isnull(row['gender']):
row['gender'] = model(row['firstname'], row['lastname'], row['location'])
return row
return df.apply(clean, axis=1)
# test implementation with stub
def test_do_not_overwrite_gender():
def model_stub(first, last, location):
return 'M'
df = pd.DataFrame({'firstname': ['John', 'Jane', 'Jim'],
'lastname': ['Doe', 'Doe', 'Doe'],
'location': ['Pittsburgh, PA', 'Rome, Italy', 'Paris, PA '],
'gender': [np.nan, 'F', np.nan]})
out = clean_gender(df, model_stub)
assert(out['gender'] ==['M', 'F', 'M']).all()Example data cleaning code that fills in missing gender information in our customer data. An external ML model (called as a remote inference service) is used to infer the gender based on the customer’s name and location. To make this code more testable, the function is decoupled from the specific API, which is now passed in as an argument. Now, we can test the cleaning code without the external API by calling the cleaning function with an alternative hardcoded implementation of the dependency (`model_stub`), which produces predictable behavior during testing. This way, multiple tests can deliberately inject different behaviors for different tests without ever having to deal with the real model inference backend.
Conceptually, test drivers and stubs are replacing the production code on both sides of the code under test. On one side, rather than calling the code from production code (e.g., from within the pipeline or from a user interface), automated unit tests act as test drivers that decide how to call the code under test. On the other side, stubs replace external dependencies (where appropriate) such that the code under test can be executed in isolation. Note that the test driver needs to set up the stub when calling the code under test, usually by passing the stub as an argument.
Testing error handling
A good approach to avoid silent mistakes in ML pipelines is to be explicit about error handling for all pipeline code: What should happen if training data misses some values? What should happen during feature engineering if an entire column is missing? What should happen if an external model inference service used during feature engineering is timing out? What should happen if the upload of the trained model fails?
There is no single correct answer to any of these questions, but engineers writing robust pipelines should consider the various error scenarios, especially regarding data quality and regarding disk and network operations. Developers can choose to (1) implement recovery mechanisms, such as filling missing values or retrying failing network connections, or to (2) signal an error by throwing an exception to be handled by the client calling the code. Monitoring how often recovery mechanisms or exceptions are triggered can help to identify when problems increase over time. Ideally, the intended error-handling behavior is documented and tested.
Both recovery mechanisms and intentional throwing of exceptions on invalid inputs or environment errors can be tested explicitly in unit tests. A unit test providing invalid inputs would either assert the fixed behavior or assert that the code terminates with an expected exception.
def test_invalid_day_of_week_data():
df = pd.DataFrame({'datetime_us': ['01/01/2020'], 'delivery_count': [1]})
with pytest.raises(ValueError):
encode_day_of_week(df) Example of a unit test that ensures that the `encode_day_of_week` function correctly rejects invalid inputs (here a wrong column name) with a ValueError.
If the code has external dependencies that may produce problems in practice (e.g., because it relies on network connections that may not always be available), it is usually a good idea to ensure that the code handles errors from those dependencies as well. To this end, stubs are a powerful mechanism to simulate faults in a test case to ensure that the system either recovers correctly from the simulated fault or throws the right exception if recovery is not possible. Stubs can be used to simulate many different kinds of defects from external components, such as dropped network connections, slow replies, and illformed responses. For example, we could inject connectivity problems, behaving as if a remote server is not available on the first try, to test that the retry mechanism recovers from a short-term outage correctly, but also that it throws an exception after the third failed attempt.
## testing retry mechanism
from retry.api import retry_call
import pytest
# stub of a network connection, sometimes failing
class FailedConnection(Connection):
remaining_failures = 0
def __init__(self, failures):
self.remaining_failures = failures
def get(self, url):
print(self.remaining_failures)
self.remaining_failures -= 1
if self.remaining_failures >= 0:
raise TimeoutError('fail')
return "success"
# function to be tested, with recovery mechanism
def get_data(connection, value):
def get(): return connection.get('https://replicate.npmjs.com/registry/'+value)
return retry_call(get,
exceptions = TimeoutError, tries=3, delay=0.1, backoff=2)
# 3 tests for no problem, recoverable problem, and not recoverable
def test_no_problem_case():
connection = FailedConnection(0)
assert get_data(connection, '') == 'success'
def test_successful_recovery():
connection = FailedConnection(2)
assert get_data(connection, '') == 'success'
def test_exception_if_unable_to_recover():
connection = FailedConnection(10)
with pytest.raises(TimeoutError):
get_data(connection, '')Example of testing a recovery mechanism for a failing network connection by using a stub for that connection that deliberately injects network problems. The code should work when there are no network problems and when there are recoverable network problems, and it should throw an exception if the problem is not recoverable with three retries.
The same kind of testing should also be applied to deployment steps in the pipeline, ensuring that failed deployments are noticed and reported correctly. Again stubs can be used to test the correct handling of situations where uploads of models failed or checksums do not match after deployment.
For error handling and recovery code, it is often a good idea to log that an issue occurred, even if the system recovered from it. Monitoring systems can then raise alarms when issues occur unusually frequently. Of course, we can also write tests to observe whether the counter was correctly increased as part of test cases testing error handling with injected faults.
from prometheus_client import Counter
connection_timeout_counter = Counter(
'connection_retry_total',
'Retry attempts on failed connections')
class RetryLogger():
def warning(self, fmt, error, delay):
connection_timeout_counter.inc()
retry_logger = RetryLogger()
def get_data(connection, value):
def get(): return connection.get('https://replicate.npmjs.com/registry/'+value)
return retry_call(get,
exceptions = TimeoutError, tries=3, delay=0.1, backoff=2,
logger = retry_logger)Example using a Prometheus counter to record every time a connection fails and is retried, which can then be monitored in dashboard and alerting infrastructure like Grafana.
Where to focus testing
Data science pipelines often contain many routine steps building on common libraries, such as pandas or scikit-learn. We usually assume that these libraries have already been tested and do not need to write our own tests to ensure that the library implements its functions correctly. For example, we would not test that scikit-learn computes the mean square error correctly, that panda’s groupby method is implemented correctly, or that Hadoop distributes the computation correctly across large datasets. In contrast, it is useful to test whether our own custom data-transformation code that uses those libraries works as intended.
Data quality checks. Any code that receives data should check for data quality and those data quality checks should be tested to ensure that the code correctly detects and possibly repairs invalid and low-quality data. Data quality code typically has two parts:
- Detection: Code analyzes whether provided data meets expectations. Data quality checks can come in many forms as discussed in chapter Data Quality, including (1) checking that any data was provided at all, (2) simple schema validation that would detect when an API provides data in a different format, and (3) more sophisticated approaches that check for stable distributions in input data.
- Repair: Code fixes the data if a problem was detected. Repair may simply remove invalid data or replace invalid or missing data with default values, but repair can also take more sophisticated actions such as computing plausible values from context.
Both detection and repair code can be tested with unit tests. Detection code is commonly a function that receives data and returns a boolean result indicating whether the data is valid. This can be tested with examples of valid and invalid data, as also illustrated with the tests for encode_day_of_week with valid and invalid data frames above. Repair code commonly is a function that receives data and returns repaired data. For this, tests can check that provided invalid data is repaired as expected. In the clean_gender example above, we tested the code that detects and replaces missing gender values (where repair is driven by a function not tested); we could also have written tests for the (external) model that predicts the value used for repair.
Generally, if repair for data quality problems is not possible or too many data quality problems are observed, the pipeline may also decide to terminate with an error. Even if repair is possible, the pipeline might report the problem to a monitoring system to observe whether the problem is common or even increasingly frequent, as illustrated for the retry mechanism in get_data. Both raising error messages intentionally and monitoring the frequency of repairs can avoid some of the common silent mistakes.
Data wrangling code. Any code that deals with transforming data — for example, for feature engineering — deserves scrutiny. Data transformations often need to deal with tricky corner cases and it is easy to introduce mistakes that can be difficult to detect. Data scientists often inspect some sample data to see whether the transformed data looks correct, but rarely systematically test for corner cases and rarely deliberately decide how to handle invalid data (e.g., throw an exception or replace with default value).
For example, the code below (variant A) from a Kaggle competition on Android apps attempts to convert textual representations of download counts (e.g., “142”, “10k”, “100.5M”) into numbers but produces wrong results for some values because one of the regular expressions matches the uppercase “K” instead of the used lowercase “k”. A simple test with the three numbers above could have found the bug. A different implementation (variant B) trying to achieve the same goal below did not anticipate that values could contain decimal points failing on inputs like “100.5M”. Note how both variants fail silently, producing incorrect results for the subsequent training step. Even if decimal points were not anticipated, tests could ensure that only anticipated values were accepted, that is only combinations of numbers followed by “k” or “M”, making sure that exceptions are raised for other inputs.
# Variant A, returns 10 for “10k”
num = data.Size.replace(r'[kM]+$', '', regex=True).astype(float)
factor = data.Size.str.extract(r'[\d\.]+([KM]+)', expand =False)
factor = factor.replace(['k','M'], [10**3, 10**6]). fillna(1)
data['Size'] = num*factor.astype(int)
# Variant B, returns 100.5000000 for “100.5M”
data["Size"]= data["Size"].replace(regex =['k'], value='000')
data["Size"]= data["Size"].replace(regex =['M'], value='000000')
data["Size"]= data["Size"].astype(str). astype(float)Training code. Even when the full training process may ingest huge data sets and take a long time, tests with small input datasets can ensure that the training code is set up correctly. For example, most API misuse issues and most mismatch issues of tensor dimensions and size in deep learning can be detected by executing the training code with small datasets. It may be useful to feed a fixed or random small dataset into the training code to assure that a model in the right format and shape is trained without exceptions. Testing the correctness of the machine-learning library is beyond the scope of what is reasonable in most projects unless a custom library was developed for the project.
Interactions with other components. The pipeline interacts with many other components of the system and many problems can occur there, for example, when loading training data, when interacting with a feature server, when uploading a serialized model, or when running A/B tests. These kinds of problems relate to the interaction of multiple components. We can test that local error handling and error reporting mechanisms work as expected, as discussed above. Beyond that, we can test the correct interaction of multiple components with integration testing and system testing to which we will return shortly in chapter Integration and System Testing.
Beyond functional correctness. Beyond testing the correctness of the pipeline implementations, it can be worth considering other qualities, such as latency, throughput, and memory needs when machine-learning pipelines operate at scale on large datasets. This can help ensure that changes to code in the pipeline do not derail resource needs for executing the pipeline. Standard libraries and profilers can be used just as in non-ML software.
Static Analysis of ML Pipelines
While there are several recent research projects to statically analyze data science code, at the time of this writing, there are few ready to use tools available. As discussed in chapter Quality Assurance Basics, static analysis can be seen as a form of automated code review that focuses on narrow specific issues, often with heuristics. If teams realize that they make certain kinds of mistakes frequently, they might be able to write a static analyzer that identifies this problem early when it occurs again.
Static analysis tools for statically typed languages, such as Java and C, are usually more advanced than those for Python and other scripting languages commonly used in data science projects. There are some static analysis tools for Python that can also be used for data science code and even within notebooks, such as Flake8, but most of them focus on style issues and simple bug patterns, including naming conventions, documentation formatting, unused variables, and code complexity checks.
Academics have developed various static analysis tools for specific kinds of issues, and we expect to see more of them in the future. Recent examples include:
- DataLinter looks for suspicious or inefficient patterns of data encoding before machine learning tasks, such as numbers encoded as strings, enums encoded as real numbers, lack of normalization of data with strong outliers, and duplicate data rows. Other researchers have suggested more patterns and tools for other potential data quality problems.
- Pythia uses static analysis to detect shape mismatch in TensorFlow programs, for example, when tensors provided to the TensorFlow library do not match in their dimensions and dimensions’ sizes.
- Leakage Analysis analyzes data science code with data-flow analysis to find instances of data leakage where training and test data are not strictly separate, possibly resulting in overfitting on test data and too optimistic accuracy results.
- PySmell and similar “code smell” detectors for data science code can detect common anti-patterns and suspicious code fragments that indicate poor coding practices, such as large amounts of poorly structured deep learning code and unwanted debugging code.
- mlint analyzes the infrastructure around pipeline code, statically detecting the use of “best engineering practices” such as using version control, using dependency management, and writing tests in a project.
- Gather is a plugin for Jupyter notebooks that statically analyzes the code structure to identify what part of the code is needed to create a specific figure or other output in the notebook. It can then create a “slice,” the subset of the notebook with only the code to create that output.
Process Integration and Test Maturity
As discussed in chapter Quality Assurance Basics, it is important to integrate quality assurance activities into the process. If developers do not write tests, never run their tests, never execute their static analysis tools, or just approve every code review without really looking at the code then they are unlikely to find problems early.
Overall, data-science code and pipeline code that is ready for production should be considered like any other code in a system, undergoing the same (and possibly additional) quality assurance steps. It benefits from the same process integration steps as traditional code, such as, automatically executing tests with continuous integration on every commit, automatically reporting coverage, and surfacing static analysis warnings during code review.
Since data science code is often developed in an exploratory fashion in a notebook before being transformed into a more robust pipeline for production, it is not common to write tests while writing the initial data science code, because much of it is thrown away anyway when experiments fail. This places a higher burden to write and test robust code when eventually migrating the pipeline for production. In a rush to get to market, there may be little incentive to step back and invest in testing when the data-science code in the notebook already shows promising results, yet quality assurance should probably be part of the milestone for releasing the model and should certainly be a prerequisite for automating regular runs of the pipeline to deploy model updates without developers in the loop. Neglecting quality assurances invites the kind of silent mistakes discussed throughout this chapter and can cause substantial effort to fix the system later; we will return to this issue in chapter Technical Debt.
Project managers should plan for quality assurance activities for pipelines, allocate time, and assign clear deliverables and responsibilities. Having an explicit checklist can help to assure that many common concerns are covered, not just functional correctness of certain data transformations. For example, a group at Google introduced the idea of an ML test score, consisting of a list of possible tests a team may perform around the pipeline, scoring a point for each of 28 concerns tested by a team and a second point for each concern where tests are automated. The 28 concerns include a range of different testable issues, such as whether a feature benefits the model, offline and online evaluation of models, code review of model code, unit testing of the pipeline code, adoption of canary releases, and monitoring for training-serving skew, grouped in the themes feature tests, model tests, ML infrastructure tests, and production monitoring.
The idea of tracking maturity of the quality assurance practices in a project and comparing scores across projects or teams can signal the importance of quality assurance to the teams and encourage the adoption and documentation of quality assurance practices as part of the process. While the specific concerns from the ML test score paper may not generalize to all projects and may be incomplete for others, they are a great starting point to discuss what quality assurance practices should be tracked or even required.
Summary
The code to transform data, to train models, and to automate the entire process from data loading to model deployment in a pipeline should undergo quality assurance just as any other code in the system. In contrast to the machine-learned model itself which requires different quality assurance strategies, pipeline code can be assured just like any other code through automated testing, code review, and static analysis. Testing is made easier by modularizing the code and minimizing dependencies. Given the exploratory nature of data science, quality assurance for pipeline code is often neglected even when transitioning from a notebook to production infrastructure, hence it is useful to make an explicit effort to integrate quality assurance into the process.
Further Reading
- List of 28 concerns that can be tested automatically around machine-learning pipelines and discussion of a test score to assess the maturity of a team’s quality-assurance practices: 🗎 Breck, Eric, Shanqing Cai, Eric Nielsen, Michael Salib, and D. Sculley. “The ML test score: A rubric for ML production readiness and technical debt reduction.” In 2017 IEEE International Conference on Big Data (Big Data), pp. 1123–1132. IEEE, 2017.
- Quality assurance is prominently covered in most textbooks on software engineering and dedicated books on testing and other quality assurance strategies exist, such as 🕮 Dustin, Elfriede. Effective software testing: 50 specific ways to improve your testing. Pearson, 2003. and 🕮 Roman, Adam. Thinking-driven testing. Springer International Publishing, 2018.
- Examples of academic papers using various static analyses for data science code: 🗎 Lagouvardos, Sifis, Julian Dolby, Neville Grech, Anastasios Antoniadis, and Yannis Smaragdakis. “Static analysis of shape in TensorFlow programs.” In Proc. European Conference on Object-Oriented Programming (ECOOP), 2020. 🗎 Yang, Chenyang, Rachel A. Brower-Sinning, Grace A. Lewis, and Christian Kästner. “Data Leakage in Notebooks: Static Detection and Better Processes.” Proc. Int’l Conf. Automated Software Engineering (2022). 🗎 Head, Andrew, Fred Hohman, Titus Barik, Steven M. Drucker, and Robert DeLine. “Managing messes in computational notebooks.” In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, pp. 1–12. 2019. 🗎 Gesi, Jiri, Siqi Liu, Jiawei Li, Iftekhar Ahmed, Nachiappan Nagappan, David Lo, Eduardo Santana de Almeida, Pavneet Singh Kochhar, and Lingfeng Bao. “Code Smells in Machine Learning Systems.” arXiv preprint arXiv:2203.00803 (2022). 🗎 van Oort, Bart, Luís Cruz, Babak Loni, and Arie van Deursen. “”Project smells” — Experiences in Analysing the Software Quality of ML Projects with mllint.” In Proc. ICSE SEIP (2022).
As all chapters, this text is released under Creative Commons 4.0 BY-SA license.